Парсинг
Yandex.Wordstat
Данные настройки оказывают влияние на сбор статистики с системы Yandex.Wordstat.
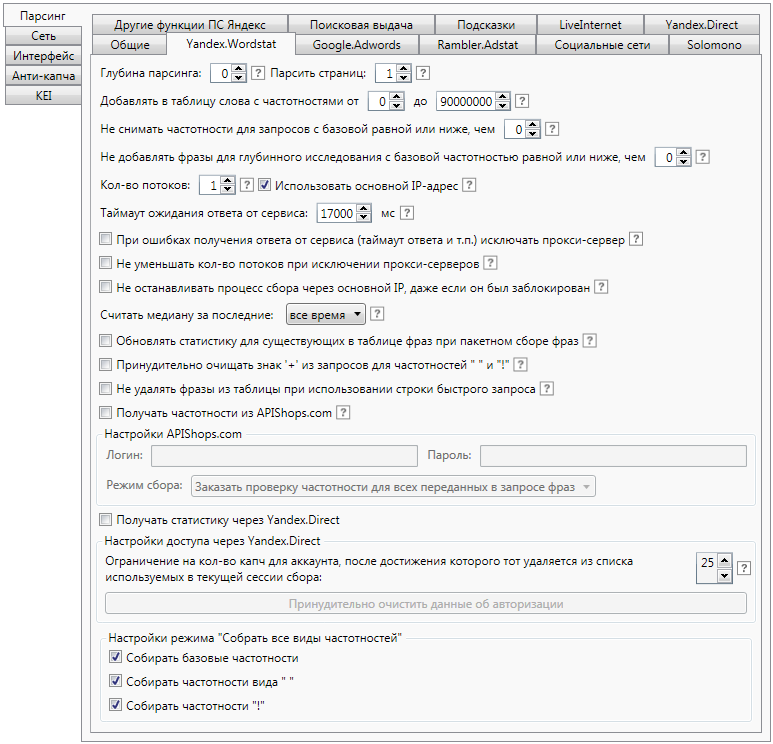
Глубина парсинга
Данный параметр отвечает за глубину исследования ключевой фразы и влияет только на сбор ключевых фраз.
Глубина исследования - это количество обходов списка слов, которая программа будет выполнять при анализе заданного ключевого слова.
Пусть глубина парсинга равна 2, а параметр "парсить страниц" установлен в значение 3. Пользователь дает программе команду собрать слова по запросу "молоко".
Программа просматривает первые 3 страницы выдачи и добавляет до 150 слов в таблицу данных. Нулевая итерация завершена. Начинается итерация #1.
Программа использует в качестве запроса полученные на нулевой итерации слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #1 завершена. Начинается итерация #2.
Программа использует в качестве запроса полученные на нулевой итерации и итерации #1 слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #2 завершена. Процесс сбора информации по слову "молоко" завершен.
Как видите, с каждым разом количество слов на обработку растет, следовательно, растет и время, необходимое на их анализ. Если Вам не требуется максимально возможное исследование тематики, то рекомендуем оставить этот параметр в значении 0, т.к. с каждой новой итерацией результат будет все меньшим (программа не добавляет в таблицу дубликаты имеющихся слов), а время, необходимое для анализа - расти с огромной скоростью.
Если Вам все же действительно необходимо выполнять глубинное исследование, то рекомендуем поставить глубину = 0, а затем следовать следующему простому алгоритму:
- запускаете пакетный сбор фраз, ждете завершения процесса;
- копируете собранные фразы в буфер обмена (через пункт "Скопировать колонку в буфер обмена" в контекстном меню заголовка колонки "Фраза"), при необходимости удалив заведомо ненужные фразы, чтобы сократить общее время сбора;
- открываете окно пакетного сбора фраз и вставляете из буфера фразы;
- запускаете сбор.
Выполнение данного простого алгоритма не должно затруднить Вас, т.к. с учетом скорости сбора фраз уже на второй итерации Вам придется выполнить эти 3 простых операции 1-2 раза в сутки или значительно реже, если список фраз будет большим.
Парсить страниц
Данный параметр отвечает за то, сколько страниц в выдаче по заданному запросу будет просматривать программа. Максимальное количество страниц в Yandex.Wordstat равно 40. На каждой странице при этом находится до 50 фраз. Таким образом, максимальное кол-во результатов по одной фразе в Wordstat - 2000. Обращаем Ваше внимание на то, что лишь для высокочастотных запросов сервис Yandex.Wordstat готов предложить Вам максимальное количество страниц.
Если Вы принципиально хотите получать результаты именно из Yandex.Wordstat, а не из других источников, то:
- можно расширить входной список слов, т.е. задать не только "капуста", но и другие уточняющие расширяющие слова: "производство капусты", "капуста цветная" и т.д.;
- можно поставить в очередь на пакетный сбор фразы, полученные на первой итерации по запросу "капуста". Это можно сделать как вручную, то и сразу поставив в "Настройках - Парсинг - Yandex.Wordstat" параметр "Глубина поиска" = 1. О преимуществах того или иного способа подробно написано в конце описания опции "Глубина поиска".
Добавлять в таблицу фразы с частотностями от ... до ...
Данный параметр позволяет избежать попадания в таблицу данных слов, базовая частотность которых не входит в указанный диапазон.
Мы рекомендуем не использовать данную функцию во избежание непредумышленной потери значимых слов, а воспользоваться системой фильтрации в таблицах данных над полным набором слов.
Не снимать частотности для фраз с базовой равной или ниже, чем ...
Данный параметр может оказаться полезным в том случае, если Вас не интересуют уточняющие частотности вида " " и "!" для запросов, чья базовая частотность ниже заданной границы.
Пусть, например, таблица имеет следующий вид, а значение параметра установлено в значение 260 000.
| Фраза | Базовая частотность | Частотность " " | Частотность "!" | |
| 1 | Молоко | 724091 | ||
| 2 | Кефир | 257017 | ||
| 3 | Творог | 272614 |
После того, как будет завершена команда на снятие всех уточняющих частотностей для Yandex.Wordstat, таблица будет иметь вид:
| Фраза | Базовая частотность | Частотность " " | Частотность "!" | |
| 1 | Молоко | 724091 | 9492 | 9101 |
| 2 | Кефир | 257017 | ||
| 3 | Творог | 272614 | 3203 | 3165 |
Для фразы "Кефир" уточняющие частотности сняты не были, т.к. базовая частотность для этого слова меньше 260 000. Данная мера экономит время, трафик, а также позволяет снизить вероятность получения капчи, исключая из проверки заведомо не интересующие Вас фразы.
Автоматически записывать 0 в колонки частотностей " " и "!", если базовая частотность равна 0
Т.к. частотности вида " " и "!" не могут быть больше базовой частотности, то можно сделать вывод о том, что если базовая частотность равна 0, то и частотности вида " " и "!" тоже равны 0. По умолчанию программа пропускает при проверке частотностей вида " " и "!" фразы, у которых базовая частотность равна 0. Если Вы включите данную опцию, то программа будет не просто пропускать эти фразы, а записывать значение 0 в соответствующие ячейки колонок частотностей вида " " и "!".
Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем ...
Данная опция позволяет сократить время сбора фраз при глубинном исследовании за счет игнорирования недостаточно популярных фраз с низкой базовой частотностью.
Механизм работает следующим образом. При глубинном исследовании программа собирает со страницы все результаты и пытается добавить каждую из собранных фраз в очередь для их последующего сканирования. Допустим, на странице было 30 фраз с частотностью от 10 000 до 4 000, 15 фраз с частотностью от 3 999 до 1000 и 5 фраз с частотностью от 999 до 0. Если Вы укажете в данной опции "Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем 999", то в очередь для глубинного исследования попадут только 45 фраз, т.к. их базовая частотность была строго больше 999. Последние же 5 фраз с частотность от 999 до 0 глубинному анализу подвергаться не будут, т.к. их частотность <= 999.
Задержки между запросами от ... до ... мс
Данная настройка отвечает за задержку между запросами к Yandex.Wordstat.
Мы не рекомендуем ставить слишком маленькие задержки, чтобы не увеличивать вероятность получить блокировку IP-адреса. На данный момент относительно безопасными, но не гарантирующими отсутствие блокировки, задержками при использовании основного IP-адреса или выделенных дорогих прокси-серверов являются значения от 20 000 до 25 000 мс.
Количество потоков
Данный параметр отвечает, в сколько потоков будет происходить сбор слов, частотностей и данных сезонности с системы Yandex.Wordstat. Мы не рекомендуем создавать больше 1 потока на один IP-адрес.
При многопоточном сборе накладывается дополнительное ограничение: кол-во рабочих поток не может превышать кол-во поставленных на обработку фраз. Другими словами, если в настройках Вы укажете 5 потоков, а в окне пакетного сбора впишете только 2 фразы, то будет запущено 2 потока, а не 5. Чтобы избежать последствия данного ограничения Вы можете добавить больше фраз или использовать в качестве входного набора фраз фразы, полученные в результате парсинга других фраз.
Таймаут ожидания ответа от сервиса
Помимо пауз между запросами (обычных таймаутов) существует понятие таймаута ожидания ответа от сервиса. Это тот период времени, который программа будет ждать ответа на отправленный в сервис запрос, прежде чем сообщит в журнале событий об ошибке и не перейдет к следующей фразе или не совершит повторный запрос.
Данный параметр может пригодиться, если Вы имеете плохое качество соединения с Интернетом или используете некачественные прокси-сервера. Также увеличение значения параметра может помочь, если сервис не отвечает из-за повышенной нагрузки. Например, для Yandex.Wordstat таймаут ожидания лучше поставить в районе 30 000 - 35 000 мс.
Внимание: мы не рекомендуем устанавливать значение меньше, чем 3 000 мс, т.к. большинство запросов будет прерываться раньше, чем их обработает сервис. Также мы не рекомендуем использовать задержку больше 50 000 мс, т.к. с большой долей вероятности можно утверждать, что если сервис или прокси не ответили в течение 50 секунд, то ответ не придет и через 100. Согласно нашим экспериментам оптимальным значением будет 30 000 - 40 000 мс.
Внимание: при установке данного параметра следует учитывать не только качество используемых прокси-серверов, но и скорость доступа в сеть и количество потоков. Например, даже при использовании самых качественных прокси-серверов, программа не будет успевать получить ответ от сервиса, если скорость доступа в сеть на каждый поток будет слишком маленькой.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Так как перед запуском процесса съема Вы устанавливали задержки между запросами исходя из количества прокси-серверов и потоков, то логично не допустить перегрузки на других "хороших" прокси-серверах, которые не были удалены из локальной очереди. Именно поэтому после исключения неработающего прокси-сервера программа завершает один поток. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то воспользуйтесь опцией "Не уменьшать кол-во потоков при исключении прокси-серверов".
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Не уменьшать кол-во потоков при исключении прокси-серверов
В процессе съема статистики некоторые из используемых прокси-сервером могут быть исключены из той очереди прокси-серверов, которую программа перебирает при отправке запросов к сервису. Так, например, удаляются забаненные в сервисе прокси-серверы, а также прокси-серверы, не отвечающие на запросы программы (последний случай регулируется опцией "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер").
В нормальном режиме работы программы, чтобы не допустить перегрузки на остальных пока еще не исключенных прокси-серверах, программа сокращает количество рабочих потоков после удаления очередного прокси-сервера. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то Вы можете дать программе команду сохранять количество потоков на неизменном уровне. Обычно это имеет смысл при работе через дешевые публичных прокси-серверы.
Не останавливать процесс сбора через основной IP, даже если он заблокирован
В случае блокировки основного IP-адреса в сервисе Yandex.Wordstat дальнейшие попытки отправить запросы через него бессмысленны, поэтому по умолчанию программа исключает его использование после блокировки. Однако, если Ваш интернет-провайдер выдает IP-адрес динамически, Вы можете изменить поведение программы. В результате этого процесс получения статистики какое-то время будет отвергаться, а затем возобновиться после того, как провайдер назначит Вам новый IP-адрес.
Принудительно очищать знак "+" из запросов для частотностей " " и "!"
Данная опция имеет значение, только для фраз, содержащих знак "+" (по умолчанию данный символ фильтруется; Вы можете настроить фильтрацию спец. символов в "Настройках - Парсинг - Общие").
Как известно, знак "+" в контексте Yandex.Wordstat имеет значение оператора, подобно оператору минус-слова "-" (например, фраза "жалюзи +на окнах"). Тем не менее, существуют фразы, где "+" имеет настоящее значение, т.е. его вводят сами пользователи, например, фраза "Notepad++".
При снятии частотностей вида " " и "!", запрос заключается в кавычки. При этом знак "+" в случае, когда он являлся оператором, теряет свой смысл. В этом случае случае его нужно отфильтровать (вырезать), что и позволяет сделать данная опция. В случае же, когда знак "+" изначально был частью самой фразы, то и в запросах вида " " и "!" он не перестает ей быть, т.е. фильтрация данного символа не требуется.
Например, для фразы в таблице "пластиковые +окна" при проверке частотности вида "!" программа сформирует запрос "!пластиковые !окна", если опция будет включена.
Не удалять запросы из таблицы при использовании строки быстрого поиска
По умолчанию при использовании строки быстрого поиска Yandex.Wordstat таблица с данными полностью очищается, т.к. данный режим был задуман именно для быстрой работы с различными фразами (для большого комплексного исследования набора фраз предусмотрен пакетный сбор).
Тем не менее, некоторым нашим пользователям оказалось удобно добивать недостающие фразы именно через строку быстрого поиска. Данная опция позволяет сохранить фразы в таблице после запуска процесса нажатием кнопки Enter.
Получать частотности из APIShop.com
Программа поддерживает режим сбора частотностей через сервис APIShops.com. Вы можете зарегистрироваться в сервисе, пополнить баланс и начать получать данные о частотностях без капчи и задержек без обращений к Yandex.Wordstat.
Подробнее о возможностях работы с сервисом.
Внимание: перед использованием услуг данного сервиса рекомендуем ознакомиться со всеми доступными методами получения статистики Yandex.Wordstat. Так, например, 4-й метод сбора через Yandex.Direct является очень скоростным и абсолютно бесплатным.
Получать статистику через Yandex.Direct
Данная опция позволяет снимать статистику Yandex.Wordstat (кроме данных сезонности запросов) через интерфейс Yandex.Direct. Для этого необходимо иметь специально зарегистрированные для сбора активированные и готовые аккаунты и прокси-серверы, чтобы минимизовать риск их блокировки.
Данный режим ничем не лучше стандартного и является резервным. Он может пригодиться лишь тогда, когда доступ к самому Yandex.Wordstat для Вашего IP или прокси-серверов, которые Вы используете, заблокирован, а к Yandex.Direct - нет.
Для запуска данного режима необходимо прописать доступ к аккаунтам Яндекс.Директа в "Настройках - Парсинг - Yandex.Direct".
Подробнее о данном режиме можно прочитать в пресс-релизе "Сбор Yandex.Wordstat через Yandex.Direct".
Внимание: не стоит путать данный режим с режимом сбора статистики из раздела "Прогноз бюджета" в Яндекс.Директе. Режим, включаемый опцией "Получать статистику через Yandex.Direct" является полным аналогом Yandex.Wordstat и не отличается повышенной производительностью.
Внимание: известны случаи, когда панель "резервного" Yandex.Wordstat для некоторых фраз выдает гораздо меньше информации в левой/правой колонке.
Внимание: доступ к Yandex.Direct также может быть заблокирован. Мы рекомендуем использовать только специально созданные для сбора данных аккаунты, т.к. автоматические запросы могут стать причиной блокировки Ваших персональных аккаунтов.
Считать медиану за последние ... месяцев
При сборе данных о сезонности фраз программа вычисляет значение медианы по данным указанного периода.
Обновлять статистику для существующих в таблице фраз при пакетном сборе фраз
Данная опция позволяет обновлять статистику (базовую частотность Yandex.Wordstat) для фраз уже находящихся в таблице фраз при пакетном сборе фраз из Yandex.Wordstat. Таким образом можно сэкономить время сбора базовой частотности для фраз в таблице, добавленных из различных источников.
Предположим, Вы одновременно запустили сбор данных из различных источников: Google.Adwords, LiveInternet и Yandex.Wordstat. По умолчанию программа добавляет в таблицу фразу (и статистику от той системы, из которой она поступила, если такая имеется) от того источника, который раньше всех остальных предоставил информацию об этой фразе. Т.е. если фраза "кисломолочные продукты" поступила сперва из Google.Adwords, а через минуту - из Yandex.Wordstat, то в таблице данных для этой фразы после ее добавления будет присутствовать лишь информация о частотностях и стоимость клика в Google.Adwords, когда как информации о базовой частотности Yandex.Wordstat будет отсутствовать, т.к. фраза была предоставлена сервисом Google.Adwords. Если Вы включите данную опцию, то программа будет обновлять статистику для фраз, уже находящихся в таблице данных. Т.е. в примере, рассмотренном выше, произойдет следующее: программа сперва добавит в таблицу фразу "кисломолочные продукты" и статистику Google.Adwords, а спустя минуту (когда Yandex.Wordstat тоже выдаст эту фразу) программа также запишет для данной фразы и базовую частотность Yandex.Wordstat.
Внимание: при работе с большими проектами данная опция может замедлять скорость сбора информации из-за необходимости проведения поиска фразы, требующей обновления, по всем существующим в проекте фразам.
Настройки режима "Собрать все виды частотностей"
Данный блок настроек позволяет определить, какие задачи будут поставлены в очередь на обработку при использовании кнопки "Собрать все виды частотностей" Yandex.Wordstat.
Google.Adwords
Данные настройки оказывают влияние на сбор статистики с системы Google.Adwords.

Глубина парсинга
Данный параметр отвечает за глубину исследования ключевой фразы и влияет только на сбор ключевых фраз.
Глубина исследования - это количество обходов списка слов, которая программа будет выполнять при анализе заданного ключевого слова.
Пусть глубина парсинга равна 2, а параметр "парсить страниц" установлен в значение 3. Пользователь дает программе команду собрать слова по запросу "молоко".
Программа просматривает первые 3 страницы выдачи и добавляет до 150 слов в таблицу данных. Нулевая итерация завершена. Начинается итерация #1.
Программа использует в качестве запроса полученные на нулевой итерации слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #1 завершена. Начинается итерация #2.
Программа использует в качестве запроса полученные на нулевой итерации и итерации #1 слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #2 завершена. Процесс сбора информации по слову "молоко" завершен.
Как видите, с каждым разом количество слов на обработку растет, следовательно, растет и время, необходимое на их анализ. Если Вам не требуется максимально возможное исследование тематики, то рекомендуем оставить этот параметр в значении 0, т.к. с каждой новой итерацией результат будет все меньшим (программа не добавляет в таблицу дубликаты имеющихся слов), а время, необходимое для анализа - расти с огромной скоростью.
Если Вам все же действительно необходимо выполнять глубинное исследование, то рекомендуем поставить глубину = 0, а затем следовать следующему простому алгоритму:
- запускаете пакетный сбор фраз, ждете завершения процесса;
- копируете собранные фразы в буфер обмена (через пункт "Скопировать колонку в буфер обмена" в контекстном меню заголовка колонки "Фраза"), при необходимости удалив заведомо ненужные фразы, чтобы сократить общее время сбора;
- открываете окно пакетного сбора фраз и вставляете из буфера фразы;
- запускаете сбор.
Выполнение данного простого алгоритма не должно затруднить Вас, т.к. с учетом скорости сбора фраз уже на второй итерации Вам придется выполнить эти 3 простых операции 1-2 раза в сутки или значительно реже, если список фраз будет большим.
Парсить страниц
Данный параметр отвечает за то, сколько страниц в выдаче по заданному запросу будет просматривать программа.
Задержки между запросами от ... до ... мс
Данная настройка позволяет установить время ожидания между запросами, отправляемыми программой.
Внимание: не ставьте слишком маленькие задержки между запросами. Система Google.Adwords может заблокировать используемый Вами для сбора статистики аккаунт или IP-адрес.
Обновлять статистику для существующих в таблице фраз при пакетном сборе фраз
Данная опция позволяет обновлять статистику Google.Adwords для фраз уже находящихся в таблице фраз при пакетном сборе фраз из Google.Adwords. Таким образом можно сэкономить время сбора статистики Google.Adwords для фраз в таблице, добавленных из различных источников.
Предположим, Вы одновременно запустили сбор данных из различных источников: LiveInternet, Yandex.Wordstat и Google.Adwords. По умолчанию программа добавляет в таблицу фразу (и статистику от той системы, из которой она поступила, если такая имеется) от того источника, который раньше всех остальных предоставил информацию об этой фразе. Т.е. если фраза "кисломолочные продукты" поступила сперва из Yandex.Wordstat, а через минуту - из Google.Adwords, то в таблице данных для этой фразы после ее добавления будет присутствовать лишь информация о базовой частотности Yandex.Wordstat, когда как информации о частотностях и стоимости клика из Google.Adwords будет отсутствовать, т.к. фраза была предоставлена сервисом Yandex.Wordstat. Если Вы включите данную опцию, то программа будет обновлять статистику для фраз уже находящихся в таблице данных. Т.е. в примере, рассмотренном выше, произойдет следующее: программа сперва добавит в таблицу фразу "кисломолочные продукты" и статистику Yandex.Wordstat, а спустя минуту (когда Google.Adwords тоже выдаст эту фразу) программа также запишет для данной фразы и статистику Google.Adwords.
Внимание: при работе с большими проектами данная опция может замедлять скорость сбора информации из-за необходимости проведения поиска фразы, требующей обновления, по всем существующим в проекте фразам.
Rambler.Adstat
Данные настройки оказывают влияние на сбор статистики с системы Rambler.Adstat. Для съема статистики с этой системы необходимо зарегистрироваться в ней и ввести данные для авторизации в интерфейс программы.
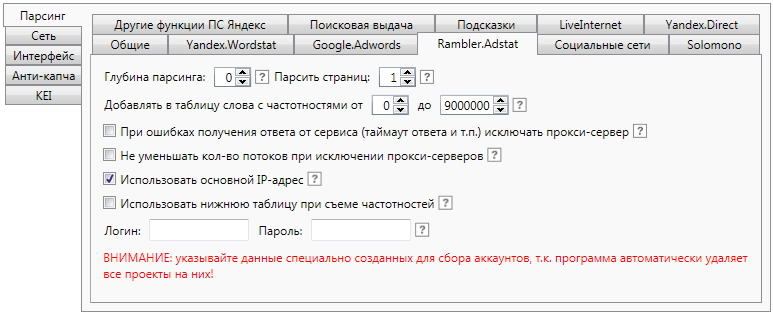
Глубина парсинга
Данный параметр отвечает за глубину исследования ключевой фразы и влияет только на сбор ключевых фраз.
Глубина исследования - это количество обходов списка слов, которая программа будет выполнять при анализе заданного ключевого слова.
Пусть глубина парсинга равна 2, а параметр "парсить страниц" установлен в значение 3. Пользователь дает программе команду собрать слова по запросу "молоко".
Программа просматривает первые 3 страницы выдачи и добавляет до 150 слов в таблицу данных. Нулевая итерация завершена. Начинается итерация #1.
Программа использует в качестве запроса полученные на нулевой итерации слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #1 завершена. Начинается итерация #2.
Программа использует в качестве запроса полученные на нулевой итерации и итерации #1 слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #2 завершена. Процесс сбора информации по слову "молоко" завершен.
Как видите, с каждым разом количество слов на обработку растет, следовательно, растет и время, необходимое на их анализ. Если Вам не требуется максимально возможное исследование тематики, то рекомендуем оставить этот параметр в значении 0, т.к. с каждой новой итерацией результат будет все меньшим (программа не добавляет в таблицу дубликаты имеющихся слов), а время, необходимое для анализа - расти с огромной скоростью.
Если Вам все же действительно необходимо выполнять глубинное исследование, то рекомендуем поставить глубину = 0, а затем следовать следующему простому алгоритму:
- запускаете пакетный сбор фраз, ждете завершения процесса;
- копируете собранные фразы в буфер обмена (через пункт "Скопировать колонку в буфер обмена" в контекстном меню заголовка колонки "Фраза"), при необходимости удалив заведомо ненужные фразы, чтобы сократить общее время сбора;
- открываете окно пакетного сбора фраз и вставляете из буфера фразы;
- запускаете сбор.
Выполнение данного простого алгоритма не должно затруднить Вас, т.к. с учетом скорости сбора фраз уже на второй итерации Вам придется выполнить эти 3 простых операции 1-2 раза в сутки или значительно реже, если список фраз будет большим.
Парсить страниц
Данный параметр отвечает за то, сколько страниц в выдаче по заданному запросу будет просматривать программа.
Добавлять в таблицу слов с частотностями от ... до ...
Данный параметр позволяет избежать попадания в таблицу данных слов, частотность которых не входит в указанный диапазон.
Мы рекомендуем не использовать данную функцию во избежание непредумышленной потери значимых слов, а воспользоваться системой фильтрации в таблицах данных над полным набором слов.
Задержки между запросами от ... до ... мс
Данная настройка отвечает за задержку между запросами к Rambler.Adstat.
Мы не рекомендуем ставить слишком маленькие задержки, чтобы не увеличивать вероятность получить блокировку IP-адреса.
Обновлять статистику для существующих в таблице фраз при пакетном сборе фраз
Данная опция позволяет обновлять статистику Rambler.Adstat для фраз уже находящихся в таблице фраз при пакетном сборе фраз из Rambler.Adstat. Таким образом можно сэкономить время сбора статистики Rambler.Adstat для фраз в таблице, добавленных из различных источников.
Предположим, Вы одновременно запустили сбор данных из различных источников: LiveInternet, Yandex.Wordstat и Rambler.Adstat. По умолчанию программа добавляет в таблицу фразу (и статистику от той системы, из которой она поступила, если такая имеется) от того источника, который раньше всех остальных предоставил информацию об этой фразе. Т.е. если фраза "кисломолочные продукты" поступила сперва из Yandex.Wordstat, а через минуту - из Rambler.Adstat, то в таблице данных для этой фразы после ее добавления будет присутствовать лишь информация о базовой частотности Yandex.Wordstat, когда как информации о частотностях Rambler.Adstat будет отсутствовать, т.к. фраза была предоставлена сервисом Yandex.Wordstat. Если Вы включите данную опцию, то программа будет обновлять статистику для фраз уже находящихся в таблице данных. Т.е. в примере, рассмотренном выше, произойдет следующее: программа сперва добавит в таблицу фразу "кисломолочные продукты" и статистику Yandex.Wordstat, а спустя минуту (когда Rambler.Adstat тоже выдаст эту фразу) программа также запишет для данной фразы и статистику Rambler.Adstat.
Внимание: при работе с большими проектами данная опция может замедлять скорость сбора информации из-за необходимости проведения поиска фразы, требующей обновления, по всем существующим в проекте фразам.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Использовать основной IP-адрес
Включение данной опции не означает, что все запросы будут производиться через основной IP-адрес. Если опция включена, то программа будет использовать основной IP-адрес с той же периодичностью, что и каждый из активных прокси-серверов. Если опция выключена, то программа не будет использовать основной IP-адрес при работе с сервисом.
Использовать нижнюю таблицу при съеме частотностей
Внимание: при сборе данных из нижней таблицы процесс затрачивает значительно больше времени. Это связано с тем, что программа отправляет не анализ не пачки по 30 фраз, а запросы, состоящие только из одной фразы.
Социальные сети
В настоящий момент программа поддерживает съем сведений о количестве людей и групп, которые находятся по указанному запросу в социальной сети В Контакте. Для съема статистики необходимо зарегистрироваться в ней и ввести данные для авторизации в интерфейс программы.
Задержки между запросами не следует ставить ниже 1500 мс, т.к. данная социальная сеть незамедлительно блокирует аккаунты, производящие слишком частые запросы.
Solomono
Данные настройки оказывают влияние на сбор статистики с системы Solomono.
Глубина исследования поисковой выдачи
При исследовании фразы в Solomono программа сканирует поисковую выдачу ПС Яндекс, а затем собирает анкоры для каждого из найденных в выдаче сайтов. Вы можете установить глубину сканирования поисковой выдачи.
Количество потоков
Данный параметр отвечает, в сколько потоков будет сбор статистики Solomono. Мы не рекомендуем создавать больше 1 потока на один IP-адрес.
При многопоточном сборе накладывается дополнительное ограничение: кол-во рабочих поток не может превышать кол-во поставленных на обработку фраз.
Yandex.Direct
Данные настройки относятся к сбору статистики Yandex.Direct.
Ограничение на кол-во капч для аккаунта, после достижения которого тот удаляется из списка используемых в текущей сессии сбора
При работе в Yandex.Direct может случиться ситуация, что на аккаунте с каждым разом все чаще станет встречаться капча. Чтобы не тратить время на обработку капчи на аккаунтах, где ранее в текущем съеме уже было обнаружено много капчи, Вы можете дать программе команду автоматически исключать такие аккаунты из очерди на использование. Таким образом, Вы даете аккаунту время "отдохнуть", а сами не тратите время на распознавание капчи на потенциально закапчеванном аккаунте.
Деактивировать на 30 минут аккаунт из очереди, если на нем встретилось 5 капчей подряд
При работе в Yandex.Direct может случиться ситуация, что на аккаунте появится вечная капча. Вы можете дать программе команду не использовать такие аккаунты в течение 30 минут, если на них подряд встретилось 5 капчей. Таким образом, Вы даете аккаунту время "отдохнуть", а сами не тратите время на распознавание капчи на закапчеванном аккаунте.
Принудительно очистить данные об авторизации
Чтобы не тратить время на авторизацию в аккаунтах, программа выполняет эту операцию один раз за сеанс работы с программой для каждого аккаунта. При этом в момент авторизации, если используются прокси-серверы, устанавливается привязка между конкретным прокси-серверов и аккаунтом (чтобы запросы от одного аккаунта не приходили каждый раз с новых прокси-серверов).
Если Вы сменили набор прокси-серверов и в этом сеансе работы с программой ранее запускали сбор статистики Yandex.Direct, то необходимо нажать данную кнопку, чтобы сбросить текущую привязку аккаунтов к ранее прописанным прокси-серверам.
Задержки между запросами от ... до ... мс
Данная настройка отвечает за задержку между запросами к Yandex.Direct.
Мы не рекомендуем ставить слишком маленькие задержки, чтобы не увеличивать вероятность получить блокировку IP-адреса.
Количество потоков
Данный параметр отвечает, в сколько потоков будет происходить сбор статистики Yandex.Direct. Мы не рекомендуем создавать больше 1 потока на один IP-адрес и аккаунт.
Использовать основной IP-адрес
Включение данной опции не означает, что все запросы будут производиться через основной IP-адрес. Если опция включена, то программа будет использовать основной IP-адрес с той же периодичностью, что и каждый из активных прокси-серверов. Если опция выключена, то программа не будет использовать основной IP-адрес при работе с сервисом.
Не использовать прокси-серверы при работе с Yandex.Direct
Специфика работы с Yandex.Direct такова, что лучше либо вообще не использовать прокси-серверы, либо использовать дорогие стабильные прокси-серверы. Но т.к. Вам может быть удобно использовать плохие публичные прокси-серверы для съема другой статистики, а для Yandex.Direct они не годятся, то Вы можете приказать программе работать с Yandex.Direct без использования прокси-серверов, игнорируя опцию "Использовать прокси-серверы" в "Настройках - Сеть".
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Так как перед запуском процесса съема Вы устанавливали задержки между запросами исходя из количества прокси-серверов и потоков, то логично не допустить перегрузки на других "хороших" прокси-серверах, которые не были удалены из локальной очереди. Именно поэтому после исключения неработающего прокси-сервера программа завершает один поток. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера/аккаунта Yandex.Direct как следствие) и хотите получить максимальную скорость съема, то воспользуйтесь опцией "Не уменьшать кол-во потоков при исключении прокси-серверов".
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Не уменьшать кол-во потоков при исключении прокси-серверов
В процессе съема статистики некоторые из используемых прокси-сервером могут быть исключены из той очереди прокси-серверов, которую программа перебирает при отправке запросов к сервису. Так, например, удаляются забаненные в сервисе прокси-сервера, а также прокси-сервера, не отвечающие на запросы программы (последний случай регулируется опцией "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер").
В нормальном режиме работы программы, чтобы не допустить перегрузка на остальных пока еще не исключенных прокси-серверах, программа сокращает количество рабочих потоков после удаления очередного прокси-сервера. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера/аккаунта Yandex.Direct как следствие) и хотите получить максимальную скорость съема, то Вы можете дать программу команду сохранять количество потоков на неизменном уровне.
Искать
Программа может отправлять в Yandex.Direct на обработку фразы в трех различных режимах:
- слово - в этом режиме программа отправляет на анализ фразы "как есть" (аналогично базовой частотности в Yandex.Wordstat);
- "слово" - в этом режиме программа заключает фразу в кавычки (аналогично частотности вида " " в Yandex.Wordstat);
- "!слово" - в этом режиме программа заключает фразу в кавычки, а также ставит перед каждым словом знак !. Т.е. из фразы красивые сапоги получится "!красивые !сапоги" (аналогично частотности вида "!" в Yandex.Wordstat).
При этом, если Вы включили опцию "Целью запуска сбора статистики является заполнение колонок частотности Yandex.Wordstat", то будет заполняться колонка базовой, " " или "!" частотности Yandex.Wordstat в зависимости от выбранного режима.
Собирать информацию о конкурентах
Программа может сканировать размещаемые в Yandex.Direct объявления конкурентов для каждой из переданных на анализ фразы. Данная операция значительно увеличивает время, необходимое для выполнения задачи, поэтому рекомендуется не включать опцию без необходимости. Сканирование ведется с использованием сервиса http://direct.yandex.ru/search?text=.
Для просмотра заголовков, содержания и ссылок объявлений нажмите на ячейку с данными конкуренции - откроется дополнительное окно.
Целью запуска сбора статистики является заполнение колонок частотности Yandex.Wordstat
Если Вы включите данную опцию, то программа будет определять список фраз с неснятыми данными на основании соответствующих колонок Yandex.Wordstat, а не по колонкам Yandex.Direct.
Для ясности рассмотрим пример. Пусть в таблице данных содержится 150 фраз, и в "Настройках - Парсинг - Общие" выбран режим сбора для несобранных (т.е. для тех фраз, для которых пока что отсутствует статистика). Предположим, что для каких-то 100 фраз уже собрана статистика Yandex.Direct (бюджет, стоимость клика и др.), а статистика в колонках Yandex.Wordstat не заполнена.
Если бы данная опция была выключена, то программа бы определила список фраз, которые нуждаются в обработке, по заполненности ячейки бюджета Yandex.Direct, т.е. на обработку бы поступили оставшиеся 50 фраз (150 - 100 = 50).
Если же данная опция включена, и, скажем, выбран режим поиска "!слово", то программа просмотрим и добавит в очередь на анализ все фразы, у которых отсутствует статистика в колонке частотности "!" по Yandex.Wordstat.
Таким образом, данную опцию следует включать, если первочередной интересующей Вас информацией в Yandex.Direct является количество показов, которые Вы бы хотели записать в колонки частотностей Yandex.Wordstat.
Внимание: по причине того, что Yandex.Direct принимается на вход пачки фраз и при необходимости "склеивает" фразы в них, то для некоторых фраз программа может не собрать статистику Yandex.Direct (соответственно, не соберется и статистика Yandex.Wordstat). Также Yandex.Direct не может принимать на обработку фразы, содержащие в себе спец. символы или кол-во слов, превосходящее 7.
Внимание: т.к. до момента отправки запросов на обработку программа не может знать, какие из фраз Yandex.Direct "склеит", а какие нет, то непосредственно перед формированием запроса программа стирает данные статистики для фраз, которые содержаться в текущем запросе на обработку, чтобы не допустить того, чтобы в таблице часть данных имела свежие актуальные результаты, а часть - результаты из прошлого съема (если, например, 5 из 100 отправленных фраз будут "склеены", то программа не сможет узнать статистику для каждой из 5 в отдельности).
Валюта
По умолчанию цены (бюджеты, стоимость клика) в программе отображаются в рублях. Если вам удобней работать с у.е. (1 у.е. = 30 руб.), Вы можете изменить отображаемую валюту при помощи данной настойки. Обращаем ваше внимание на то, что после изменения типа валюты необходимо переоткрыть проект.
Автоматически перезапускать процесс при ошибке "Сервис недоступен" через 120 секунд
Иногда сервис Yandex.Direct временно прекращает свою работу с сообщением "Сервис недоступен". Вы можете приказать программа автоматически совершать повторную попытку собрать статистику через 120 секунд, включив данную опцию.
Поисковая выдача
Данные настройки, вообще говоря, имеют отношение к поисковой выдаче по запросам для ПС Яндекс и Google. Настройки этой вкладки условно разделены на три блока: Yandex, Google и общий для обеих ПС блок.
Настройки блока Yandex
Использовать Yandex.XML
Данная опция позволяет программе просматривать поисковую выдачу ПС Яндекс через сервис Yandex.XML. Данный сервис представляет данные в формате XML и практически полностью исключает возможность появления капчи.
Внимание: сервис Yandex.XML не предлагает стандартного способа определения релевантных страниц, поэтому "кустарный вариант" запроса может выдавать не самые точные результаты и не для всех запросов.
Для того, чтобы настроить программу на работу через Yandex.XML, включите опцию "Использовать Yandex.XML". Далее Вы можете выбрать обычный или пакетный режим работы с Yandex.XML.
Обычный режим работы просто в настройке и удобен в использовании. Он нужен, если у Вас есть 1 аккаунт Yandex.XML, готовый к работе. Для активации данного режима просто введите туда адрес для совершения запросов, который Вам выдали в панели Yandex.XML.
Пакетный режим нужен лишь в том случае, когда у Вас есть несколько аккаунтов Yandex.XML. Для его активации введите в соответствующее ему поле данные аккаунтов в специальном формате. Программа поддерживает 2 формата ввода:
-
Формат LOGIN:PASSWORD
MyAccountName:MyPassword
MySecondAccountName:MySecondPasswordДля использования этого формата просто введите несколько пар логин:пароль. Программа будет автоматически заходить в панель управления доступом Yandex.XML и прописывать на текущий аккаунт Ваш IP-адрес. При достижении лимита запросов программа перейдет к следующего аккаунту, предварительно очистив настройки предыдущего.
Внимание: сервис Yandex.XML не допускает одновременного нахождения двух и более аккаунтов, привязанных на один IP-адрес, поэтому если в результате какого-либо сбоя, аварийного завершения программы или иных нестандартных случаев программе не удалось сбросить настройки на последнем используемом аккаунте, могут возникнуть проблемы с использованием доступа через Yandex.XML. В этом случае необходимо вручную сбросить настройки IP-адреса на всех когда-либо прописанных в программу аккаунтах.
-
Формат #ProxyServer:ProxyPort:ProxyLogin:ProxyPassword:YandexUserAccontLogin:AccessKey
#127.0.0.1:8080:MyProxyLogin:MyProxyPassword:MyYandexAccountName:03.53418088:807330ae1f86ff127ba9bea41284b47f
#127.0.0.1:8080:MyProxyLogin:MyProxyPassword:MyYandexAccountName:03.53418088:807330ae1f86ff127ba9bea41284b47fНекоторые сервисы предлагают пакеты IP-адресов с закрепленными за ними аккаунтами Yandex.XML. Программа будет автоматически переключаться между указанными аккаунтами и работать через прописанные в строке инициализации прокси-сервера. Обратите внимание на необходимость ввода символа "#" в начале каждой новой строки.
Внимание: программа не допускает одновременного использования двух различных форматов. Другими словами, в случае использования сервиса Yandex.XML все аккаунты должны быть заданы в первом или втором формате, но не в вперемешку.
Задержки между запросами от ... до ... мс
Данная настройка отвечает за задержку между запросами к поисковой системе Yandex при сканировании поисковой выдачи (съем позиций, анализ релевантных страниц, сбор составляющих KEI по Yandex и др.).
Мы не рекомендуем ставить слишком маленькие задержки, чтобы не увеличивать вероятность получить капчу или блокировку на IP-адрес.
Количество потоков
Данный параметр отвечает, в сколько потоков будет происходить сбор статистики, использующей данные поисковой выдачи ПС Яндекс. Т.е. это анализ релевантных страниц, сбор позиций и рекомендаций, сбор составляющих поисковой выдачи, определение корректности словоформы на основе поисковой выдачи ПС Яндекс и др.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Так как перед запуском процесса съема Вы устанавливали задержки между запросами исходя из количества прокси-серверов и потоков, то логично не допустить перегрузки на других "хороших" прокси-серверах, которые не были удалены из локальной очереди. Именно поэтому после исключения неработающего прокси-сервера программа завершает один поток. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то воспользуйтесь опцией "Не уменьшать кол-во потоков при исключении прокси-серверов".
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Не уменьшать кол-во потоков при исключении прокси-серверов
В процессе съема статистики некоторые из используемых прокси-сервером могут быть исключены из той очереди прокси-серверов, которую программа перебирает при отправке запросов к сервису. Так, например, удаляются забаненные в сервисе прокси-сервера, а также прокси-сервера, не отвечающие на запросы программы (последний случай регулируется опцией "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер").
В нормальном режиме работы программы, чтобы не допустить перегрузки на остальных пока еще не исключенных прокси-серверах, программа сокращает количество рабочих потоков после удаления очередного прокси-сервера. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то Вы можете дать программу команду сохранять количество потоков на неизменном уровне.
Домен
Вы можете задать предпочтительный домен ПС Яндекс, который будет использовать при сканировании поисковой выдачи ПС Яндекс в функциях сбора статистики, использующих поисковую выдачу.
Кодировка URL в кириллице
Если страницы исследуемых сайтов содержать кириллицу в своих именах, и она корректно не отображается в программе при снятии позиций или определении релевантных страниц, попробуйте выбрать одну из двух кодировок: UTF8 или WIN-1251.
Настройки блока Google
Домен
Вы можете задать предпочтительный домен ПС Google, который будет использовать при сканировании поисковой выдачи ПС Google в функциях сбора статистики, использующих поисковую выдачу.
Дополнительные параметры для GET-запроса к ПС Google
Вы можете модифицировать строку GET-запроса к ПС Google, указав дополнительные параметры. Пример: hl=ru&near=chicago.
Задержки между запросами от ... до ... мс
Данная настройка отвечает за задержку между запросами к поисковой системе Google при сканировании поисковой выдачи (съем позиций, анализ релевантных страниц, сбор составляющих KEI по Google и др.).
Мы не рекомендуем ставить слишком маленькие задержки, чтобы не увеличивать вероятность получить капчу или блокировку на IP-адрес.
Количество потоков
Данный параметр отвечает, в сколько потоков будет происходить сбор статистики, использующей данные поисковой выдачи ПС Google. Т.е. это сбор позиций, анализ релевантных страниц и др. Мы не рекомендуем создавать больше 1 потока на один IP-адрес.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Так как перед запуском процесса съема Вы устанавливали задержки между запросами исходя из количества прокси-серверов и потоков, то логично не допустить перегрузки на других "хороших" прокси-серверах, которые не были удалены из локальной очереди. Именно поэтому после исключения неработающего прокси-сервера программа завершает один поток. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то воспользуйтесь опцией "Не уменьшать кол-во потоков при исключении прокси-серверов".
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Не уменьшать кол-во потоков при исключении прокси-серверов
В процессе съема статистики некоторые из используемых прокси-сервером могут быть исключены из той очереди прокси-серверов, которую программа перебирает при отправке запросов к сервису. Так, например, удаляются забаненные в сервисе прокси-сервера, а также прокси-сервера, не отвечающие на запросы программы (последний случай регулируется опцией "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер").
В нормальном режиме работы программы, чтобы не допустить перегрузки на остальных пока еще не исключенных прокси-серверах, программа сокращает количество рабочих потоков после удаления очередного прокси-сервера. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то Вы можете дать программу команду сохранять количество потоков на неизменном уровне.
Настройки блока Mail
Задержки между запросами от ... до ... мс
Данная настройка отвечает за задержку между запросами к поисковой системе Mail при сканировании поисковой выдачи (съем позиций, анализ релевантных страниц, сбор составляющих KEI по Mail и др.).
Мы не рекомендуем ставить слишком маленькие задержки, чтобы не увеличивать вероятность получить капчу или блокировку на IP-адрес.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Так как перед запуском процесса съема Вы устанавливали задержки между запросами исходя из количества прокси-серверов и потоков, то логично не допустить перегрузки на других "хороших" прокси-серверах, которые не были удалены из локальной очереди. Именно поэтому после исключения неработающего прокси-сервера программа завершает один поток. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то воспользуйтесь опцией "Не уменьшать кол-во потоков при исключении прокси-серверов".
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Не уменьшать кол-во потоков при исключении прокси-серверов
В процессе съема статистики некоторые из используемых прокси-сервером могут быть исключены из той очереди прокси-серверов, которую программа перебирает при отправке запросов к сервису. Так, например, удаляются забаненные в сервисе прокси-сервера, а также прокси-сервера, не отвечающие на запросы программы (последний случай регулируется опцией "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер").
В нормальном режиме работы программы, чтобы не допустить перегрузки на остальных пока еще не исключенных прокси-серверах, программа сокращает количество рабочих потоков после удаления очередного прокси-сервера. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то Вы можете дать программу команду сохранять количество потоков на неизменном уровне.
Настройки общего блока
Кодировка URL в кириллице
Если страницы Вашего исследуемого сайта имеют кириллические наименования, и программа читает их в неверной кодировке, Вы можете попробовать изменить кодировку и снять статистику заново (позиции, релевантные страницы, рекомендации и др.).
Не просматривать глубже ... позиции
Данная настройки отвечает за то, сколько позиций будет просматривать программа при съеме позиций.
Например, Ваш сайт находится на 34 позиции по запросу "молоко" и на 23 позиции по запросу "кефир".
Если в настройках Вы установите "не просматривать глубже 30 позиции", то при сборе позиций программа поставит напротив запроса "молоко" значение -1, т.к. в указанных пределах видимости сайт не был обнаружен.
Кол-во запрашиваемых результатов
При съеме позиций программа делает запросы к поисковых системам до тех пор, пока сайт не будет найден в поисковой выдаче. Если в указанном диапазоне в настройке "Не просматривать глубже ... позиции" сайт не был найден, то в ячейку записывается "Нет данных". При необходимости Вы можете сократить время сбора и уменьшить кол-во запросов к поисковым системам, если будете запрашивать сразу по 50 результатов на странице, а не по 10.
Побочным эффектом применения этой опции может стать незначительная погрешность при определении позиций, т.к. иногда поисковая выдача "по 50 результатов на странице" отличается от стандартной.
Учитывать позиции для поддоменов
Активация данной опции позволяет учитывать позиции поддоменов указанного при съеме позиций сайта в поисковой выдаче. Например, страница, находящаяся по адресу shop.moscow.ru/user_info.html будет учтена при съеме позиций для сайта moscow.ru.
Искать слово или "слово"
При определении релевантных страниц некоторые пользователи предпочитают использовать точное вхождение в кавычках. Вы можете включить этот режим при помощи данной настройки.
Подсказки
Данные настройки оказывают влияние на процесс сбора поисковых подсказок, а также функций, работающих на их основе - определение корректности словоформы.
Задержки между запросами от ... до ... мс
Данная настройка позволяет установить время ожидания между запросами, отправляемыми программой, к поисковым системам при получении поисковых подсказок, а также при определении корректности словоформы на основе поисковых подсказок.
Мы не рекомендуем ставить эти значения слишком маленькими (особенно при больших объемах парсинга), т.к. маленькие задержки могут привести к блокировке Вашего IP-адреса. При средних объемах оптимальными значениями являются 500 - 1500 мс.
Глубина парсинга
Данный параметр отвечает за глубину исследования ключевой фразы и влияет только на сбор ключевых фраз.
Глубина исследования - это количество обходов списка слов, которая программа будет выполнять при анализе заданного ключевого слова.
Пусть глубина парсинга равна 2. Пользователь дает программе команду собрать слова по запросу "молоко".
Программа просматривает имещиеся поисковых подсказки и добавляет их в таблицу данных. Нулевая итерация завершена. Начинается итерация #1.
Программа использует в качестве запроса полученные на нулевой итерации слова и просматривает поисковые подсказки по каждому из них. Итерация #1 завершена. Начинается итерация #2.
Программа использует в качестве запроса полученные на нулевой итерации и итерации #1 слова и просматривает поисковые подсказки по каждому из них. Итерация #2 завершена. Процесс сбора информации по слову "молоко" завершен.
Как видите, с каждым разом количество слов на обработку растет, следовательно, растет и время, необходимое на их анализ. Если Вам не требуется максимально возможное исследование тематики, то рекомендуем оставить этот параметр в значении 0, т.к. с каждой новой итерацией результат будет все меньшим (программа не добавляет в таблицу дубликаты имеющихся слов), а время, необходимое для анализа - расти с огромной скоростью.
Если Вам все же действительно необходимо выполнять глубинное исследование, то рекомендуем поставить глубину = 0, а затем следовать следующему простому алгоритму:
- запускаете пакетный сбор фраз, ждете завершения процесса;
- копируете собранные фразы в буфер обмена (через пункт "Скопировать колонку в буфер обмена" в контекстном меню заголовка колонки "Фраза"), при необходимости удалив заведомо ненужные фразы, чтобы сократить общее время сбора;
- открываете окно пакетного сбора фраз и вставляете из буфера фразы;
- запускаете сбор.
Выполнение данного простого алгоритма не должно затруднить Вас, т.к. с учетом скорости сбора фраз уже на второй итерации Вам придется выполнить эти 3 простых операции 1-2 раза в сутки или значительно реже, если список фраз будет большим.
Собирать только ТОП подсказок без перебора и пробела после фразы
Опция деактивирует перебор окончаний и продолжений фраз, в результате чего программа совершает прямые запросы к поисковым системам без подстановки пробела после фразы. Т.е. собираются только те подсказки, которые высвечиваются при обычном вводе фразы в поисковое поле. За счет отсутствия переборов вариантов сбор подсказок в данном режиме происходит крайне быстро, но приносит меньшее количество результатов.
Набор символов для перебора окончаний
Вы можете указать набор символов, который будет перебираться в конце указанных для сбора фраз. Например, при сборе фразы "колбас" программа поочередно переберет варианты "колбаса", "колбасы", "колбасн" (вероятнее всего, будут получены такие подсказки как "колбасные") и др.
Этот метод позволяет собрать словоформы слов и имеет эффект при задании неполных слов для сбора (если Вы будете перебирать кириллицу и задавать исходное слово "москва", то на запрос "москваа", "москван", "москваы" вряд ли найдутся осмысленные подсказки. Если же Вы зададите для поиска "моск", то будут собраны подсказки "москвы", "москва", "московские" и др.)
Не активируйте данный режим без явной необходимости, т.к. его активация приведет к значительному увеличению времени сбора информации за счет необходимости перебора дополнительных вариантов.
Набор символов для перебора фраз
Вы можете узакать набор символов, который будет перебираться в конце указанных для сбора фраз через пробел. Например, при сборе фразы "колбаса" программа поочередно переберет варианты "колбаса а", "колбаса б", "колбаса в" и др.
Этот метод позволяет собрать максимальное количество подсказок. Например, на автоматически сформированный программой запрос "колбаса с" будут предложены такие подсказки как "колбаса состав", "колбаса соленая" и др. Таким образом, можно собрать не только ТОП подсказки, но и НЧ.
Внимание: в сочетании с перебором окончаний процесс может сильно затянуться, т.к. сперва будут собраны все варианты подсказок с различными окончаниями, а затем каждая из них пройдет процесс перебора продолжений через пробел. Не отмечайте ненужные символы для перебора и не используйте оба режима без явной необходимости, т.к. во-первых, это займет слишком много времени, во-вторых, увеличивается количество запросов к поисковым системам, что увеличивает вероятность применения санкций в отношении Вас.
Настройки блока Google
Дополнительные параметры для GET-запроса к ПС Google
Вы можете модифицировать строку GET-запроса к ПС Google, указав дополнительные параметры. Пример: hl=ru&near=chicago.
Домен
Данная настройка отвечает за то, какой домен ПС Google будет использоваться при работе с данной поисковой системой при сборе поисковых подсказок.
Настройки блока Yandex
Регион
Вы можете самостоятельно задать регион или выбрать режим автоматического определения на основе используемого при обращении к поисковой системе IP-адреса.
Внимание: автоматическое определение на основе IP-адреса неэффективно при использовании прокси-серверов, т.к. будет опряделяться именно их теорриториальная принадлежность, а не Ваша.
Регион в ПС Yandex
Здесь можно указать код региона ПС Яндекс, который будет отправляться в запросе на получение поисковых подсказок, если Вы выбрали режим самостоятельного задания региона. Список кодов регионов можно получить по ссылке: http://help.yandex.ru/xml/?id=1112737.
Количество потоков
Данный параметр отвечает, в сколько потоков будет происходить сбор поисковых подсказок и определение корректности словоформ на основе поисковых подсказок. Мы не рекомендуем создавать больше 1 потока на один IP-адрес.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Так как перед запуском процесса съема Вы устанавливали задержки между запросами исходя из количества прокси-серверов и потоков, то логично не допустить перегрузки на других "хороших" прокси-серверах, которые не были удалены из локальной очереди. Именно поэтому после исключения неработающего прокси-сервера программа завершает один поток. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то воспользуйтесь опцией "Не уменьшать кол-во потоков при исключении прокси-серверов".
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Не уменьшать кол-во потоков при исключении прокси-серверов
В процессе съема статистики некоторые из используемых прокси-сервером могут быть исключены из той очереди прокси-серверов, которую программа перебирает при отправке запросов к сервису. Так, например, удаляются забаненные в сервисе прокси-сервера, а также прокси-сервера, не отвечающие на запросы программы (последний случай регулируется опцией "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер").
В нормальном режиме работы программы, чтобы не допустить перегрузки на остальных пока еще не исключенных прокси-серверах, программа сокращает количество рабочих потоков после удаления очередного прокси-сервера. Если Вы не беспокоитесь о перегрузках (капча и бан прокси-сервера как следствие) и хотите получить максимальную скорость съема, то Вы можете дать программу команду сохранять количество потоков на неизменном уровне.
LiveInternet
Данные настройки оказывают влияние на процесс взаимодействия программы с сервисом LiveInternet.
Записывать источник (сайт) в поле комментариев
Если опция включена, то при сборе фраз из счетчика LiveInternet адрес сайта-источника будет записываться в поле комментариев для каждой из собранных фраз.
Использовать основной IP-адрес
Включение данной опции не означает, что все запросы будут производиться через основной IP-адрес. Если опция включена, то программа будет использовать основной IP-адрес с той же периодичностью, что и каждый из активных прокси-серверов. Если опция выключена, то программа не будет использовать основной IP-адрес при работе с сервисом.
Задержки между запросами от ... до ... мс
Данная настройка позволяет установить время ожидания между запросами, отправляемыми программой, к поисковым системам.
Мы не рекомендуем ставить эти значения слишком маленькими (особенно при больших объемах парсинга), т.к. маленькие задержки могут привести к блокировке Вашего IP-адреса.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер
При запуске процесса съема программа добавляет в список прокси-серверов отмеченные в настройках прокси-сервера. Далее программа поочередно работает с каждым прокси-сервером из этого списка. Вы можете увеличить скорость сбора информации, если будете удалять из этого списка прокси-серверов "плохие", т.е. те, которые не отвечают программе на запросы (или которым не отвечает сервис, а те в свою очередь не отвечают программе).
Обращаем Ваше внимание на то, что данная опция удаляет прокси-сервера из локальной очереди прокси-серверов, а не из общей (локальная очередь формируется при запуске процесса съема). Другими словами, список прокси-серверов в "Настройках - Сеть" не изменится.
Рекомендации
Данные настройки оказывают влияние на сбор рекомендаций.
Собирать до ... рекомендаций на запрос
При помощи данной опции Вы можете ограничить количество собираемых программой рекомендаций к каждому запросу.
Похожие поисковые запросы
Данные настройки оказывают влияние на сбор похожих поисковых запросов из поисковой выдачи.
Глубина парсинга
Данный параметр отвечает за глубину исследования ключевой фразы и влияет только на сбор ключевых фраз.
Глубина исследования - это количество обходов списка слов, которая программа будет выполнять при анализе заданного ключевого слова.
Пусть глубина парсинга равна 2, а параметр "парсить страниц" установлен в значение 3. Пользователь дает программе команду собрать слова по запросу "молоко".
Программа просматривает первые 3 страницы выдачи и добавляет до 150 слов в таблицу данных. Нулевая итерация завершена. Начинается итерация #1.
Программа использует в качестве запроса полученные на нулевой итерации слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #1 завершена. Начинается итерация #2.
Программа использует в качестве запроса полученные на нулевой итерации и итерации #1 слова и просматривает первые 3 страницы выдачи по каждому из них. Итерация #2 завершена. Процесс сбора информации по слову "молоко" завершен.
Как видите, с каждым разом количество слов на обработку растет, следовательно, растет и время, необходимое на их анализ. Если Вам не требуется максимально возможное исследование тематики, то рекомендуем оставить этот параметр в значении 0, т.к. с каждой новой итерацией результат будет все меньшим (программа не добавляет в таблицу дубликаты имеющихся слов), а время, необходимое для анализа - расти с огромной скоростью.
Если Вам все же действительно необходимо выполнять глубинное исследование, то рекомендуем поставить глубину = 0, а затем следовать следующему простому алгоритму:
- запускаете пакетный сбор фраз, ждете завершения процесса;
- копируете собранные фразы в буфер обмена (через пункт "Скопировать колонку в буфер обмена" в контекстном меню заголовка колонки "Фраза"), при необходимости удалив заведомо ненужные фразы, чтобы сократить общее время сбора;
- открываете окно пакетного сбора фраз и вставляете из буфера фразы;
- запускаете сбор.
Выполнение данного простого алгоритма не должно затруднить Вас, т.к. с учетом скорости сбора фраз уже на второй итерации Вам придется выполнить эти 3 простых операции 1-2 раза в сутки или значительно реже, если список фраз будет большим.
Общие
Данные настройки являются общими для большинства процессов парсинга.
Добавлять в таблицу фразы, содержащие не более ... слов
Данное ограничение позволяет отсекать слишком длинные фразы при попытке их добавления в таблицы данных через кнопку "Добавить" из группы кнопок "Операции с таблицей" или при сборе слов с каких-либо систем статистики, поисковых систем.
Кол-во повторных попыток загрузки страниц
В случае возникновения некритических ошибок при загрузке страниц программа будет повторять запрос к тому или иному сервису не менее указанного в данном параметре числа раз.
Таумаут ожидания ответа от сервиса
Помимо задержек между запросами существует понятие таймаута ожидания ответа от сервиса. Это тот период времени, который программа будет ждать ответа на отправленный в сервис запрос, прежде чем сообщит в журнале событий об ошибке и не перейдет к следующей фразе или не совершит повторный запрос.
Данный параметр может пригодиться, если Вы имеет плохое качество соединения с Интернетом или используете некачественные прокси-сервера.
Внимание: мы не рекомендуем устанавливать значение меньше, чем 3 000 мс, т.к. большинство запросов будет прерываться раньше, чем их обработает сервис. Также мы не рекомендуем использовать задержку больше 50 000 мс, т.к. с большой долей вероятности можно утверждать, что если сервис или прокси не ответили в течение 50 секунд, то ответ не придет и через 100. Согласно нашим экспериментам оптимальным значением будет 30 000 - 40 000 мс.
Внимание: при установке данного параметра следует учитывать не только качество используемых прокси-серверов, но и скорость доступа в сеть и количество потоков. Например, даже при использовании самых качественных прокси-серверов, программа не будет успевать получить ответ от сервиса, если скорость доступа в сеть на каждый поток будет слишком маленькой.
Режим сбора
Данная настройка отвечает за то, какие строки в таблицах данных поступят на анализ в ту или иную систему: отмеченные флажком строки или строки, для которых отсутствуют собранные значения в полях, соответствующих этой системе.
Пусть таблица имеет вид:
| Фраза | Базовая частотность | Частотность " " | Частотность "!" | |
| V | Молоко | 724091 | 9492 | |
| Кефир | 257017 | |||
| V | Творог | 272614 |
Если Вы установили режим парсинга в значение "Отмеченные записи", то при сборе частотностей вида " " программа проанализирует слова "Молоко" и "Творог", т.к. они отмечены флажками. Если же некоторые из этих слов уже имели снятую частотность вида " ", то программа обновит эти данные на актуальные.
Если Вы установили режим парсинга в значение "Строки с неполученными данными", то при сборе частотностей вида " " программа проанализирует только слова "Кефир" и "Творог", т.к. частотность вида " " для слова "Молоко" уже была известна.
Если Вы установили режим парсинга в значение "Строки с неполученными данными или отмеченные, если такие есть", то при сборе программа поставит в очередь на анализ все фразы, для которых нет данных (аналогично режиму "Строки с неполученными данными"), а также строки, которые отмечены флажками (вне зависимсоти от того, имеются ли для них данные или нет). При этом отмеченные флажками строки, не имеющие данных будут обработаны только один раз. Другими словами, очередь содержит только уникальные значения.
Ускорение сбора данных
Включение данной опции позволяет ускорить процесс съема статистики за счет использования нашей он-лайн базы ключевых фраз. За счет уменьшения количества запросов к оригинальным поставщикам данных Вы уменьшаете вероятность получить капчу, блокировку IP-адреса.
Так как база физически не может содержать в себе информацию обо всех существующих фразах, то для некоторых фраз статистика может отсутствовать. В этом случае данные статистики будут получены напрямую из сервиса поставщика данных.
Вы можете указать максимальный возраст данных, который бы вас устроил. В случае, если в базе отсутствует информация для указанной фразы с учетом выставленного периода кеширования, программа получит и отобразит актуальные данные напрямую из источника данных.
Удалять из слов спец. символы
Данная настройка позволяет фильтровать нежелательные символы во всех поступающих в программу фразах. Вы можете самостоятельно пополнить список нежелательных символов, отредактировав закрепленное за данной настройкой текстовое поле.
Заменять на пробельный символ символы
Данная настройка дополняет предыдущую настройку "Удалять из слов спец. символы", позволяя не удалять, а заменять на символ пробела нежелательные символы.
Например, Вы собираете ключевые слова по теме "ноутбуки". Некоторые модели содержат в себе нежелательные спец. символы. Во фразе "Sony Vaio VGN-NW2ZRF/N" - это знак "-" и "/". Вырезав их полностью, Вы получите новую несуществующую модель "Sony Vaio VGNNW2ZRFN". Замена этих символов на пробел позволяет получить приемлемый вариант "Sony Vaio VGN NW2ZRF N".
Приводить слова в нижний регистр
Данная настройка перед добавлением новых фраз в таблицы данных приводить их в нижний регистр.
Минимальный бюджет у ссылочных аггрегаторов
Вы можете искусственно ограничить минимальный бюджет, получаемый от ссылочных аггрегаторов. Например, если Вы считаете, что бюджет на продвижение не может быть меньше 30 рублей и установите в данной настройке значение 30, то если в процессе съема статистики со ссылочных аггрегаторов (SeoPult, Rookee, Web Effector...) для некоторой фразы будет получено значение меньшее, чем 30 (например, 18 рублей), то в результате в таблицу все равно будет записано значение 30. При этом стоимость клика также будет вычисляться по формуле: 30 / кол-во_переходов.
Не учитывать бюджет MegaIndex при расчете среднего бюджета
Известно, что бюджет, рассчитываемый в системе MegaIndex, значительно превосходит бюджеты, вычисляемые в других ссылочных аггрегаторах, т.к. он является не просто ссылочным бюджетом. Вы можете не использовать данное значение при вычислении средних бюджетов по аггрегаторам, включив данную опцию.
Сеть
Программа поддерживает работу через HTTP прокси-сервера (в том числе и с защитой доступа по паролю).
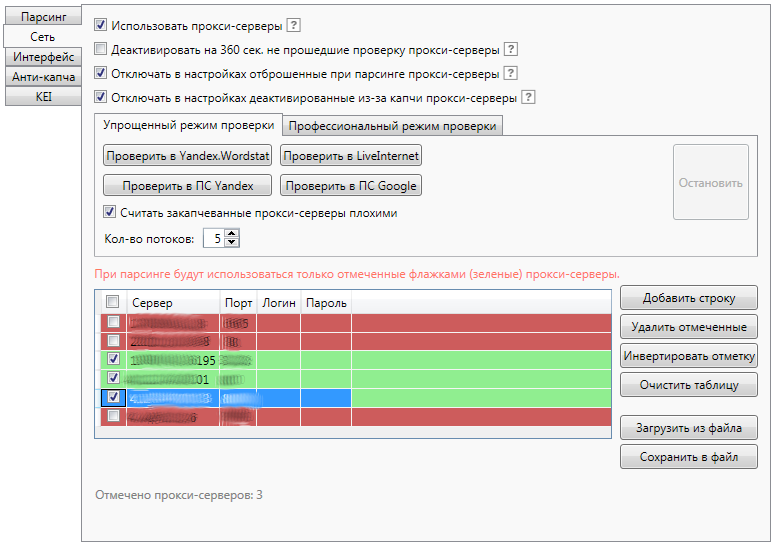
Вы можете загрузить список прокси-серверов из файла или сформировать его вручную, нажимая кнопку "Добавить строку" и прописывая данные прокси-сервера в таблицу. Сформированный список можно экспортировать при помощи кнопки "Сохранить в файл".
Для того, чтобы удалить строки из таблицы, необходимо отметить флажком интересующие Вас элементы и воспользоваться кнопкой "Удалить отмеченные".
Внимание: программа будет использовать в работе только отмеченные флажком строки.
Вы можете провести анализ списка прокси-серверов на доступность. В Key Collector предусмотрено 2 режима проверки: упрощенный и профессиональный". Упрощенный режим требует от Вас лишь указания количества потоков, в которое будет производиться анализ, и нажатия на кнопку той системы, в которой Вы бы хотите проверить Ваши прокси-сервера (при проверке через Yandex.Wordstat будут также удалены забаненные прокси-сервера). В профессиональном же режиме можно дополнительно указать время ожидания ответа от прокси-сервера, а также текст, который программа будет пытаться найти на странице выбранного в раскрывающемся списка сайта.
После проверки для удобства можно удалить недоступные прокси-сервера. Проще всего это сделать путем инвертирования отметки при помощи кнопки "Инвертировать отметку" и удаления отмеченных элементов через кнопку "Удалить отмеченные". Не забудьте пометить все оставшиеся активные сервера флажками.
Внимание: мы не рекомендуем пользоваться бесплатными анонимными прокси-серверами, т.к. их качество редко соответствует приемлемому уровню. Некоторые из них уже заблокированы или поставлены на капчу поисковыми системами, другие - работают крайне медленно или попросту становятся недоступными через некоторое время после их последней проверки. Кроме того, они могут вносить в отдаваемый сервером код дополнительные блоки (рекламу, системную информацию, ошибки), что может мешать работе программы.
Использовать прокси-серверы
При включении данной опции программа начинает использовать отмеченные флажками (зеленые) прокси-сервера из таблицы прокси-серверов.
Внимание: сбор статистики Google.Adwords является исключением: при сборе статистики Google.Adwords учитываются только системные настройки прокси-сервера, которые устанавливаются в "Панели управления - Свойства обозревателя".
Деактивировать на 360 сек. не прошедшие проверку прокси-серверы
Если в процессе сбора статистики через прокси-сервер программа получила ошибку, и если данная опция включена, программа может выполнить быструю проверку доступности прокси-сервера и в случае его недоступности исключить его из очереди прокси-серверов на 360 секунд. По истечении штрафного времени прокси-сервер вновь начнет принимать участие в процессе сбора информации, если он не будет удален или отфильтрован по другим причинам.
Отключать в настройках отброшенные при парсинге прокси-серверы
Если в процессе сбора статистики из той или иной системы прокси-сервер был вычеркнут из очереди (из-за его блокировки или недоступности + включенной опции "При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер"), то Вы можете приказать программе автоматически выключать данный прокси-сервер в таблице прокси-серверов. Таким образом, при повторном запуске процесса сбора отброшенные и деактивированные глобально прокси-серверы уже не будут участвовать в сборе статистики, что сократит необходимое для завершения задачи время.
Отключать в настройках деактивированные из-за капчи прокси-серверы
В некоторых системах (Yandex.Wordstat, например) распознавание капчи может оказаться бессмысленным, т.к. при попадании на капчу она начинает появляеться для каждого следующего запроса. Кроме того, может случиться так, что Вы работаете через подборку прокси-серверов низкого качества и не желаете тратить время и ресурсы на распознавание капчи на прокси-серверах, которыми пользуется еще сотня другая человек. В этом случае Вы можете настроить программу такими образом, чтобы она автоматически выключала в таблице прокси-серверов те, на которых была встречена капча.
При использовании хороших выделенных прокси-серверов рекомендуется распознавать капчу, а не пропускать ее (кроме Yandex.Wordstat).
Интерфейс
Экспорт
Данная вкладка содержит настройки экспортирования результатов работы программы.
Добавлять к ценам, %
Вы можете установить дополнительную надбавку в процентах, которая будет приплюсовываться в файлах экспорта к значениям, выражающим какую-либо стоимость.
Например, установив надбавку 20%, в файле экспорта для ячейки из колонки стоимости продвижения по версии Rookee, имеющей значение 1000 руб., будет записано значение с надбавкой, т.е. 1200 руб.
Добавлять строку "ИТОГО"
Если Вы включите данную опцию, в файлах экспорта программа будет добавлять дополнительную строку суммирования результатов "ИТОГО".
Автоматически открывать файл после экспортирования
Данная опция позволяет в один клик экспортировать результаты и тут же открывать их в ассоциированном с данным расширением файла приложении.
Использовать в имени файла маркер текущего времени
При использовании функции автоматического открытия файла экспорта в некоторых случаях может понадобиться, чтобы файл экпорта не записывался поверх предыдущего, а сохранялся отдельно (например, если предыдущий результат экспортирования не закрыт, то возникнет ошибка записи файла, так как тот используется в другой программе).
Формат экспорта
Вы можете выбрать формат экспорта, с которым будет работать программа: MS Excel 2007 (*.xlsx) или CSV.
При использовании формата XLSX будут экспортированы все имеющиеся в проекте пользовательские вкладки. Экспортирование в данный формат происходит медленней, чем в CSV.
При использовании формата CSV будут экспортированы данные только из текущей просматриваемой пользовательской вкладки. Вы можете самостоятельно определить разделитель между значениями и символ, в который они будут заключаться.
Расширенный формат экспортирования релевантных страниц в XLSX
При активации данной опции в файл экспорта XLSX будет попадать не только текущая релевантная страница, но и дополнительные варианты из раскрывающегося меню. При этом страница в MS Excel будет оснащена вторым скрывающимся уровнем данных.
Выгружать словоформы ПС Яндекс вместо "Да/Нет"
Если данная опция включена, то при экспортировании колонки правильной словоформы по данным ПС Яндекс в файл будут записываться сами словоформы, а не их правильность ("Да/Нет").
Выгружать в SAPE, MainLink, Rookee URL страниц из позиций, а не из релевантных страниц
При включении этой опции в выгрузку будут попадать страницы, найденные при съеме позиций, а не страницы, найденные в ходе анализа релевантных страниц.
Выгружать в SAPE, MainLink, Rookee URL страниц из Google.Analytics
Если для фразы отсутствует релевантная страница и страница, найденная в ходе сканирования позиций, то при данная опция позволит выгрузить целевую страницу из колонки Google.Analytics.
Настройки вида файла экспорта
Вы можете указать, какие колонки должны присутствовать в файле экспорта.
Прочее
Данная вкладка содержит большинство настроек, имеющих отношение к интерфейсу программы.
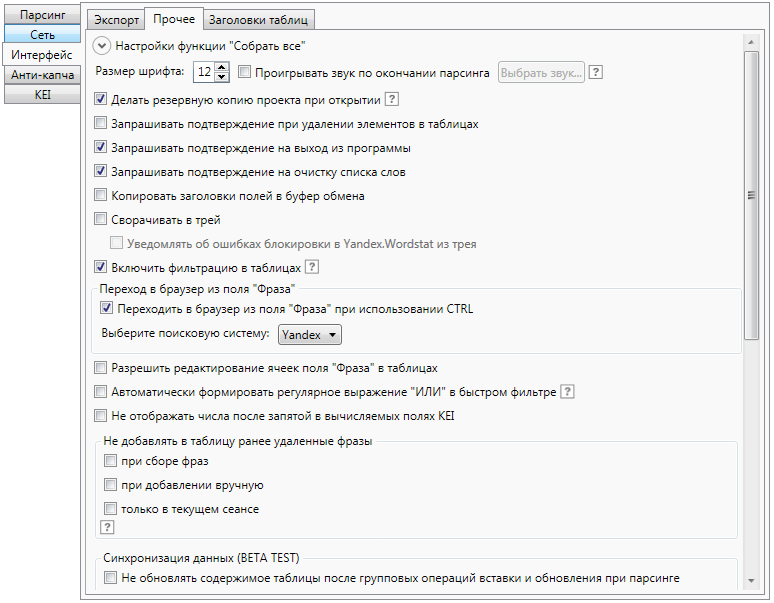
Настройки функции "Собрать все"
Вкладка "Сбор данных" содержит функцию "Собрать все", вызов которой приводит к автоматическому запуску всех настроенных для выполнения процессов сбора информации.
Вы можете отметить интересующие Вас элементы, и при нажатии кнопки "Собрать все" из группы кнопок "Сбор ключевых слов и статистики" указанные процессы будут запущены.
Размер шрифта
Данная настройка отвечает за размер шрифта в таблицах данных.
Проигрывать звук по окончании парсинга
Вы можете назначить звук, который будет воспроизводиться программой по окончании парсинга. Для этого необходимо активировать опцию "Проигрывать звук по окончании парсинга" и выбрать подходящий звуковой файл в формате WAV при помощи кнопки "Выбрать звук".
Делать резервную копию проекта при открытии
Данная функция делает резервную копию проектов перед их открытием. Резервные копии сохраняются в директории Project Backups в папке с программой.
Внимание: резервная копия обновляется лишь один раз в сутки. Другими словами, если Вы 5 раз подряд откроете проект с одним и тем же именем, резервная копия будет создана или обновлена лишь перед первым его открытием.
Не перепаковывать проект при открытии
По умолчанию при загрузке проекта программа выполняет его дефрагментацию (оптимизирует его структуру и уменьшает размер проекта за счет физического удаления удаленных из проекта фраз. При работе с большими проектами (1 млн фраз) операция дефрагментации может занимать довольно много времени. Вы можете отключить данную операцию по своему усмотрению.
Внимание: не рекомендуется отключать дефрагментацию без необходимости.
Запрашивать подтверждение при удалении элементов в таблицах
Данная настройка отвечает за запрос подтверждения на удаление строк из таблиц данных.
Запрашивать подтверждение на выход из программы
Данная настройка отвечает за запрос подтверждения на выход из программы.
Запрашивать подтверждение на очистку списка слов
Данная настройка отвечает за запрос подтверждения на очистку списка слов в окнах пакетного ввода.
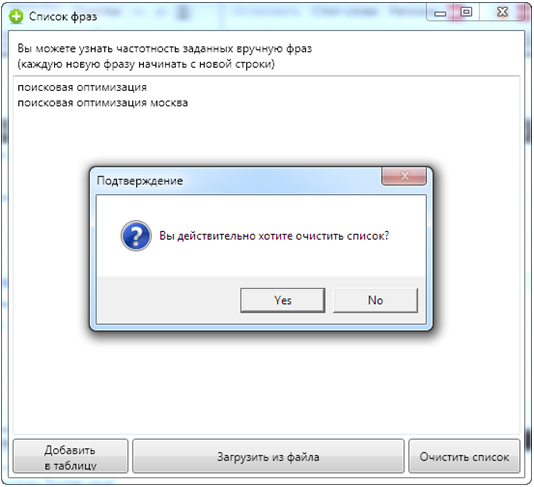
Копировать заголовки полей в буфер обмена
При копировании ячеек из таблиц данных в буфер обмена Вы можете указать программе, что та добавляла заголовки колонок, которым эти ячейки принадлежат.
Если Вы включите данную опцию, содержание буфера обмена будет иметь вид:
Фраза
фурнитура для окон
окна для дачи
боковое окно
Если Вы выключите данную опцию, содержание буфера обмена будет иметь вид:
фурнитура для окон
окна для дачи
боковое окно
Сохранять настройки вида таблиц для каждой вкладки в отдельности в файле проекта
Если данная опция активирована, то программа будет автоматически сохранять настройки вида таблицы (размер, расположение и видимость колонок) для каждой вкладки в отдельности в файл проекта. При последующей загрузке данного проекта настройки будут восстановлены.
Сохранять настройки фильтрации для каждой вкладки в отдельности в файле проекта
Если данная опция активирована, то программа будет автоматически сохранять настройки фильтрации для каждой вкладки в отдельности в файл проекта. При последующей загрузке данного проекта настройки будут восстановлены.
Сворачивать в трей
Если данная опция активирована, при загрузке проектов в таблицах будут сбрасываться все установленные настройки фильтрации.
Включить фильтрацию в таблицах
Эта настройка отвечает за наличие в таблицах данных возможности устанавливать пользовательские условия фильтрации.
Переходить в браузер из поля "Фраза" при использовании CTRL
Если данная опция включена, при нажатии левой кнопкой мыши на ячейку в колонке "Фраза" и зажатой клавишей Ctrl будет совершен переход в браузер на страницу выдачи ПС Яндекс по этому запросу.
Разрешить редактирование ячеек поля "Фраза" в таблицах
Данная настройка позволяет пользователю редактировать слова в таблицах.
Для начала редактирования дважды кликните по ячейке, для завершения - нажмите клавишу ввода или сбросьте фокус на другую ячейку.
Автоматически формировать регулярное выражение "ИЛИ" в быстром фильтре
Данная настройка включает автоматическую генерацию регулярного выражения в быстром фильтре при введение двух и более фраз.
Если Вы введете в быстрый фильтр "СЛОВО1 СЛОВО2", то автоматически сгенерированное регулярное выражение будет иметь вид (СЛОВО1(\S|\s)*?СЛОВО2(\S|\s)*?)|(СЛОВО2(\S|\s)*?СЛОВО1(\S|\s)*?), которое сможет найти в таблице все фразы, содержащие одновременно последовательности символов "СЛОВО1" и "СЛОВО2" в любом порядке.
Режим скроллинга
Программа предлагает два режима прокрутки в таблицах: непрерывный (при перемещении ползунка прокрутки содержимое таблицы будет немедленно обновляться) и сегментированный (при перемещении ползунка прокрутки содержимое таблицы будет оставаться на месте до тех пор, пока Вы не отпустите ползунок).
Внимание: непрерывная прокрутка расходует дополнительные системные ресурсы.
Действие пробела
При работе с таблицами данных иногда удобно пользоваться клавишей пробела для отметки строк. Данная настройка задает реакцию на нажатие пробела - отметку активной строки или отметку выделенного диапазона строк.
Настройки блока "Не добавлять в таблицу ранее удаленные фразы"
Данные настройки позволяют тонко настроить процесс работы с ключевыми словами в таблицах данных.
Допустим, Вы удалили 40 фраз по той причине, что они Вас не интересуют. При отключенной опции "Не добавлять в таблицу ранее удаленные фразы" при сборе фраз из открытых источников ранее удаленные фразы могут снова попасть в таблицу. Если Вы активируете опцию "при сборе фраз", то этого не прозойдет. Контроль удаленных фраз при добавлении слов вручную через кнопку "Добавить" осуществляет опция "при добавлении вручную".
Если Вы включили хотя бы одну из опций "при сборе фраз" или "при добавлении вручную", то по умолчанию информация об удаленных фразах будет храниться "вечно". Если Вы хотите, чтобы удаленные Вами нежетельные фразы не появлялись лишь при последнем сенсе работы с проектом, активируйте опцию "только в текущем сеансе".
Сбросить все настройки таблиц
Нажатие этой кнопки очищает все заданные пользователем изменения в настройках вида таблиц: видимость и ширину колонок, их порядок и т.д.
Сбросить настройки порядка колонок в таблицах
Нажатие этой кнопки сбрасывает заданный пользователем порядок колонок на стандартный.
Заголовки таблиц
Данная вкладка позволяет переопределить стандартные заголовки колонок в таблицах данных.
Вы можете задать как собственную текстовую подпись, так и иконку. Оптимальное разрежение иконки - 16х16 пикселей.
Анти-капча
Antigate
Программа поддерживает работу с сервисом автоматического распознавания капчи Antigate (http://antigate.com).
Для использования этой возможности зарегистрируйтесь на сайте сервиса и вставьте 32-символьный ключ доступа в настройки программы. Ключ доступа можно получить на странице "Распознавание - Ключ доступа".
MegaIndex API
Программа поддерживает работу с сервисом MegaIndex API (http://api.megaindex.ru/).
Настроив программу на работу с данным сервисом, Вы можете снимать данные с поисковой выдачи Yandex и Google. Сервис является альтернативой использованию прокси при работе с поисковой выдачей Yandex и Google.
Общие настройки
Данная вкладка содержит общие настройки для работы с капчей.

Автоматически переключать прокси-сервер при встрече капчи
Если Вы не хотите тратить время и ресурсы на распознавание капчи, Вы можете включить режим, при котором при встрече капчи на прокси-сервере тот переключается на следующий по очереди и запрос повторяется.
Не рекомендуется использовать данную опцию при использовании хороших выделенных прокси-серверов при сборе статистики из поисковой выдачи, где одного удачного распознавания капчи хватает на большое количество следующих запросов.
KEI
Данная вкладка определяет настройки при съеме данных из группы KEI.
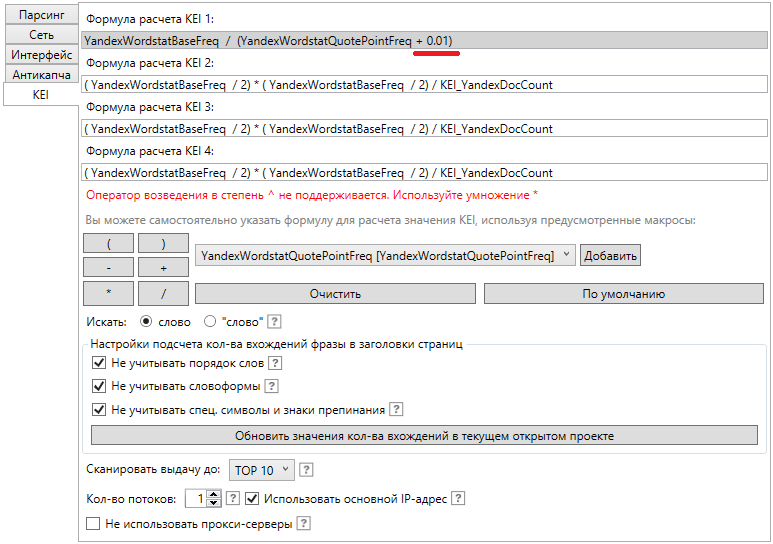
Вы можете составить до четырех формул расчета значения KEI, используя доступные макросы, выбираемые в раскрывающемся списке.
Кроме того, Вы можете выбрать режим запроса поисковой фразы: слово или "слово". Этот режим особенно сильно будет влиять на параметр конкуренции.
Внимание: для того, чтобы программа вычисляла значение KEI как дробное, необходимо один из операндов сделать дробным (например, добавив к нему 0.001 - см. скриншот).
Искать
При определении составляющих KEI некоторые пользователи предпочитают использовать точное вхождение в кавычках. Вы можете включить этот режим при помощи данной настройки. В этом случае к поисковой системе будет формироваться запрос: "молоко" (с кавычками), если в таблице было написано просто молоко.
При подсчете кол-ва вхождений фразы в заголовки не учитывать порядок слов
Если опция выключена, то программа будет искать в заголовках страниц вхождение фразы c учетом порядка слов. Если опция включена, то порядок слов при поиске учитываться не будет.
Например, если опция выключена, то для того, чтобы программа засчитала вхождение фразы "Nokia купить", заголовок страницы должен содержать точно такую же фразу "Nokia купить". Если же опция включена, и порядок не учитывается, то в заголовке просто в любом месте должны встретиться слова "Nokia" и "купить".
При подсчете кол-ва вхождений фразы в заголовки не учитывать словоформы
Если опция выключена, то программа будет искать в заголовках страниц вхождение фразы c учетом словоформ слов (окончания будут влиять на результат). Если опция включена, то словоформы при поиске учитываться не будут.
Например, если опция выключена, то для того, чтобы программа засчитала вхождение фразы "копченая колбаса", заголовок страницы должен содержать точно такие же словоформы слов "копченая" и "колбаса" (например, "лучшая копченая колбаса в мире"). Если же опция включена, и словоформы не учитываются, то в заголовке просто должны содержаться те же слова, но не обязательно в той же словоформе (например, "завод копченых колбас").
При подсчете кол-ва вхождений фразы в заголовки не учитывать спец. символы и знаки препинания
Если опция выключена, то программа будет искать в заголовках страниц вхождение фразы c учетом спец. символов и знаков препинания. Если опция включена, то спец. символы и знаки препинания при поиске учитываться не будут.
Например, если опция выключена, то для того, чтобы программа засчитала вхождение фразы "онлайн магазин", заголовок страницы должен содержать точно такое слово "онлайн магазин" (без дефиса!) (например, "оптовый онлайн магазин"). Если же опция включена, и спец. символы и знаки препинания не учитываются, то в заголовке просто должны содержаться те же слова без учета знаков (например, "заказать через онлайн-магазин").
Сканировать выдачу до TOP ...
Данный параметр отвечает за количество позиций в поисковой выдаче, которые будут просмотрены для составления данных составляющих KEI: количество главных страниц, количество точных вхождений заданной фразы в заголовки страниц.
Количество потоков
Данный параметр отвечает, в сколько потоков будет происходить сбор составляющих KEI. Мы не рекомендуем создавать больше 1 потока на один IP-адрес.
Не использовать прокси-серверы
При включении данной опции программа будет игнорировать прокси-серверы, заданные в Настройках - Сеть.